首个医疗视频理解大模型开源,手术安全评估任务准确率达89.7%,未来将融合具身智能
近日,联影智能宣布,正式开源“元智”医疗视频理解大模型——uAI Nexus MedVLM。
近日,联影智能宣布,正式开源“元智”医疗视频理解大模型——uAI Nexus MedVLM。
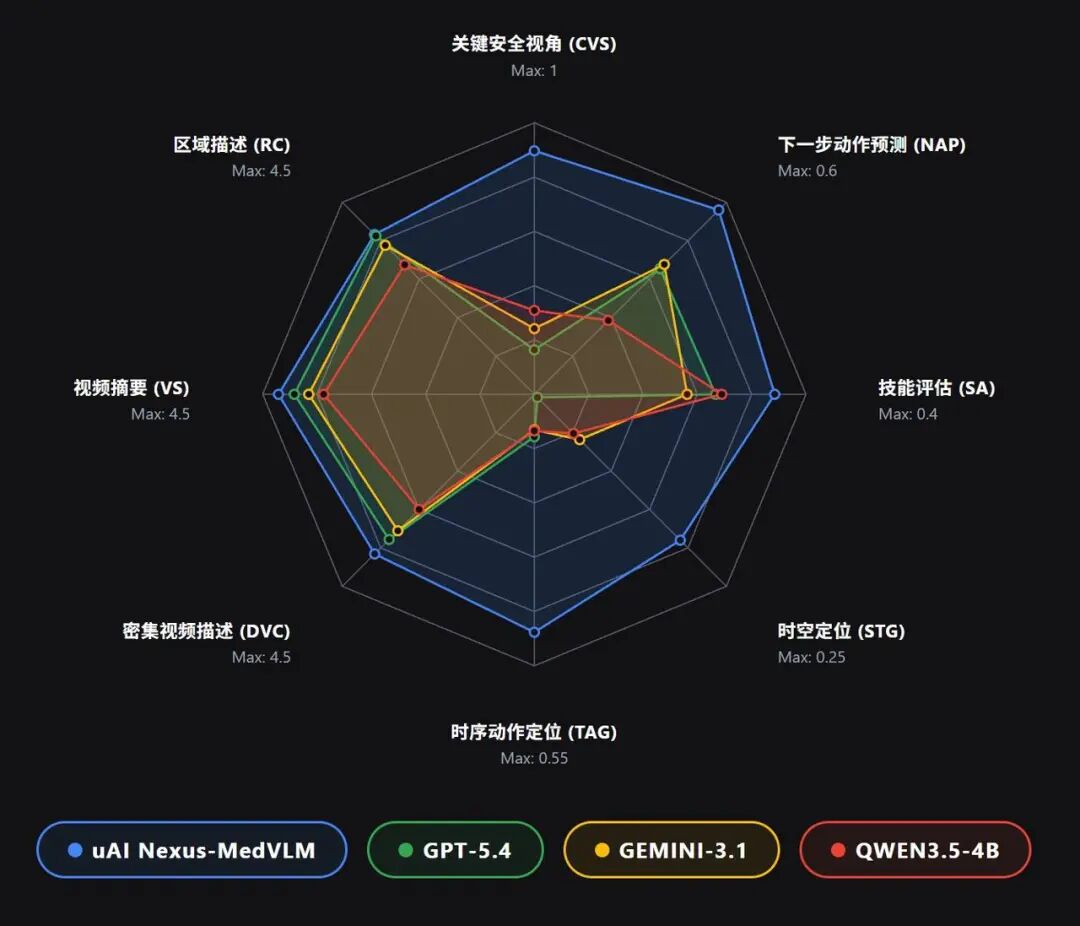
据介绍,该模型依托超 53 万“逐帧级”精细标注数据训练而成,在仅 4B/7B 参数规模下,手术安全评估任务准确率达 89.7%,远高于 GPT-5.4(准确率 16.4%)和Gemini-3.1 (准确率 24.2%);在时空动作定位任务中,预测区域与真实区域的交并比(mIoU)是 Gemini-3.1 的 3.2 倍、GPT-5.4 的 47 倍;在手术视频报告生成方面,满分5分的情况下,视频报告生成评分达到 4.24 分,高于 GPT-5.4(3.98 分)与 Gemini-3.1(3.74 分)。
团队通过构建覆盖531850组视频-指令配对的海量标注数据集,对手术器械轨迹、空间定位、关键动作及风险指标进行了逐帧精细标注,最终赋予了模型“感知-推理-生成”的全栈临床智能能力。模型覆盖内镜、腹腔镜、机器人手术、护理操作等多种临床场景,在视频摘要(VS)、关键安全视野评估(CVS)、下一步操作预测(NAP)、技能评估(SA)、时间动作定位(TAG)、密集视频描述(DVC)、区域级描述(RC)等核心任务中表现卓越。通过开源模型,开发者仅需上传真实医疗视频,即可体验多种视频理解场景,大幅降低应用门槛。相关成果已被 IEEE 国际计算机视觉与模式识别会议(CVPR 2026)收录。
该模型在临床决策中,可为复杂病例提供客观的数据支撑与决策参考,降低医疗差错风险;在质控管理中,可构建术前规划、术中监管、术后总结的全流程闭环,推动科室质控实现全量数字化审查;在教学培训领域,可将专家经验转化为可量化、可复用的标准体系,自动拆解手术流程、精准定位操作差异,让年轻医师的学习精确到“秒级”和“特定器械交互”,缩短医疗人才培养周期,缓解基层医疗机构手术经验不足、医疗资源分布不均的问题。
除开源模型外,联影智能还同步开放了一套由 6245 个视频-指令对构成的标准测试集,为医疗视频理解提供更具可比性的评测基准,同时还发布了“医疗视频理解大模型榜单”,并邀请全球全球开发者参与打榜。
联影智能方面表示,未来“元智”大模型有潜力融合具身智能,共同形成“视觉感知-逻辑推理-物理执行”的完整能力闭环,推动复杂医疗操作迈向全面数字化、结构化与智能化。

关注大健康Pai 官方微信:djkpai我们将定期推送医健科技产业最新资讯